Robin Yadav, Year 3
Abstract
Recently, drones have become useful tools for firefighters. Wildfire drones survey the fire and provide critical monitoring information that firefighters need to reduce wildfire damage. However, human-operated drones are not the most efficient allocation of time and resources for firefighters. Furthermore, they are difficult to operate in high stress situations and can put firefighters at risk. This paper investigates a potential method to automate wildfire drones using deep learning object detection, deep reinforcement learning and imitation learning. Several versions of the You Only Look Once (YOLO) models were trained to recognize fire. A simulation environment of a fire front and fire break was created using Unreal Engine and Microsoft AirSim. A drone object was trained using imitation learning (behavioral cloning) and reinforcement learning, more specifically Deep Q-Learning, to fly along the fire break parallel to the fire front. Several experiments were conducted to tune the reward function and hyperparameters of the models and test transfer learning of a DQN agent from a behavioral cloning policy. The best performing agent was achieved when transfer learning is used, the positive reward region is kept relatively small and a very negative reward is given for crossing the threshold distances. Using these techniques, the drone learned to navigate the entirety of the fire front while maintaining a consistent distance from the fire front with very little deviations. This demonstrates potential for practical application of autonomous wildfire drones to monitor and survey stabilized fire fronts along a fire break.
Introduction
Every year, approximately eight thousand wildfires burn across Canada and damage over 2.5 million hectares of land (Statistics Canada, 2019). Just in British Columbia alone, an average of 300,000 hectares of land is burnt by wildfires causing 260 million dollars in destruction every year (BC Wildfire Service, 2020). Recently, drones have become useful tools for firefighters. (Shen, 2018) Wildfire drones survey the fire and provide critical monitoring information that firefighters need to reduce the damage a wildfire can cause. Tasks such as fire line monitoring, hot spot location, wildfire and destruction mapping and real time aerial video feed assessment are conducted using wildfire drones (Savvides, 2018). However, human-operated drones are not the most efficient allocation of time and resources for firefighters. Furthermore, they are difficult to operate in high stress situations and can put firefighters at risk. (Savvides, 2018)
This paper investigates a potential method to automate wildfire drones using deep learning. Autonomous drones allow firefighters to focus on more important tasks while being able to effectively receive critical monitoring information to control and reduce damage caused by wildfires. For example, autonomous drones would be able to fly along a fire line, map the burning area and send data to firefighters.
It is critical to have an accurate fire detection system as a base for drone automation and wildfire monitoring. Most previous video-based fire detection systems use hand-crafted features such as spatial, temporal and color characteristics of fire to perform recognition (Phillips et al., 2002, Toulouse et al., 2015, Toulouse et al, 2017). Although in recent years, there has been an interest in leveraging convolutional neural networks (CNN) for fire image classification. A CNN adjusted from GoogleNet was used to classify images as fire or non-fire (Muhammed et al., 2018). Other developments include a CNN which performs patch identification on images of fire (Zhang et al., 2016). However, those CNNs lack localization functionality, so they cannot identify where the fire is in an image. I will implement fire detection using state-of-the-art object detection models which can identify the position of the fire within an image without the use of hand-crafted features. This approach allows for robust and accurate fire detection while still maintaining the ability to run in real time on low-cost devices (Vidyavani et al., 2019). Also, the models are very versatile because the training data includes fires in many different contexts, from small localized fires to larger forest and bush fires. The use of deep learning object detection models for fire recognition and automating drones can offer an efficient system for wildfire monitoring. Previous work was done using deep learning object detection models to identify fire in images (Yadav 2020). However, this paper aims to use a larger dataset allowing for more versatility and robust fire detection.
This paper proposes automating wildfire drones using deep learning object detection, reinforcement learning and imitation learning. Reinforcement learning and imitation learning consists of an agent and environment which operate as a Markov Decision Process (MDP). The fundamental assumption of an MDP is the next state is only dependent on the current state. The agent takes actions determined by a policy. A policy is a function which maps states to actions. The action is carried out in the environment and the environment returns the next state and the reward the agent receives. The goal of reinforcement learning is to learn a policy which maxims the expected value of the cumulative reward over trajectories.
Previous work in wildfire drone automation proposed the idea of GPS navigation of drone swarms guided by high altitude UAVs. (Afghah et al., 2019) However, high altitude UAVs are very expensive and drone swarms are very difficult to coordinate (Zhu et al., 2015). Some developments of autonomous drones for disaster relief reconstruct indoor settings in 3D and using those reconstructions for autonomous flight and performing intricate movements (Apvrille et al., 2014). My approach focuses on the automation of a single drone independent of other drones in the area. The movement of the drone is determined by the location of the surrounding fire and is not limited by obstacles and barriers which are present in an indoor setting. Furthermore, this project aims to use Deep Q-Learning (DQN) (a reinforcement learning algorithm) and behavioural cloning (a form of imitation learning) to automate wildfire drones. Through these techniques, the drone learns to navigate wildfires using information from images taken by its front camera.
Deep Q-learning/network (DQN) is a value-based reinforcement learning method in which a neural network is trained to approximate the optimal Q-function. The Q-function is a state-action value function that outputs the expected reward of a trajectory beginning at a certain state-action pair and then following the optimal Q-function. By this definition the Q-function measures how “good” taking a specific action at a certain state is for the agent. In a DQN, the Q-function is represented by a neural network where the outputs of the neural network are the Q-values each action. The first stage of the DQN process involves the agent collecting transitions (the current state, the current action, the next state and reward) which are stored in a replay buffer. The weights of the target Q-network and a current Q-network are randomly initialized. The target Q-network is used to calculate target Q-values and the current Q-network is used to calculate current Q-values. The loss function is defined to be the mean squared error between the target Q-values and current Q-values. Using the mean squared error loss, a gradient descent update is performed to update the parameters of the current Q-network. The parameters of the target Q-network are updated with the parameters of the current Q-network every set number of iterations. As the training progresses, the current Q-network becomes a better approximator of the value of a state-action pair. This is useful because the policy can implicitly defined by taking the action that maximizes the Q-function at a certain state.Behavioural cloning is a form of supervised learning. A human expert controls the agent and collects observations. The observations are labelled with the corresponding action the human expert took at each timestep. A policy which is represented by a neural network is trained to map images from observations.
Procedure
A dataset of approximately four thousand RGB images of fire was constructed by web scraping from the internet and obtaining data from smaller datasets. The fire images are labeled using bounding boxes. Data augmentation was applied to the images (e.g., rotation, scaling, translation and cropping) to increase the size of the dataset. Object detection for fire recognition was performed using the YOLO (You Only Look Once) (Redmond and Farhadi, 2017) deep learning models. In particular, YOLOv4, YOLOv3 and YOLOv3-Tiny models were trained.
A simulation environment was created in the 3D game engine and simulation platform Unreal Engine (Unreal Engine version 4.26). The environment was integrated with the Microsoft AirSim plugin (Shah et al., 2017) which provides the necessary physics and API for drone control. A forest, fire front, fire break and drone object were modeled in this environment. A drone object is trained using reinforcement learning and imitation learning to autonomously fly along the firebreak (parallel to the fire front) and monitor the wildfire. The firebreak includes curved sections and straight sections which makes the reinforcement learning task more challenging and better simulates reality. Figure 1 shows an example image of the environment.

Figure 1: An example image of the environment where the drone is taking off
The action space for the drone includes three actions: go forward, move right or move left. The turning angle was tuned through experimentation to achieve the best performance. The observation space was an image taken by the front camera of the drone and rescaled to 84 by 84 pixels. The use of image data as input to the Q-network is important as fire recognition plays a critical role in learning to fly along the fire front. Throughout the training process, the Q-network can learn to recognize patterns of fire in the images in relation to the distance from the fire front(e.g. there is more fire when closer to the fire front and less fire when farther) which will allow the drone to better navigate the fire front.
The reward function for the DQN agent was defined as an exponential decay based on the distance from the fire front and the velocity of the drone. The distance is calculated using built-in functions from Microsoft Airsim. Beta is a constant and was tuned through experimentation to determine the value which leads to the best performance. Experimentation with the Beta value and the reward for crossing the threshold distances was conducted to observe the values that led to the best performance. Also, episodes were terminated if the reward was lower than -10. Figure 2 shows a simplified diagram of the different reward regions.
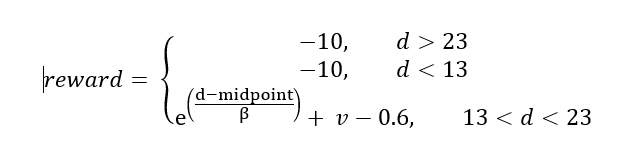
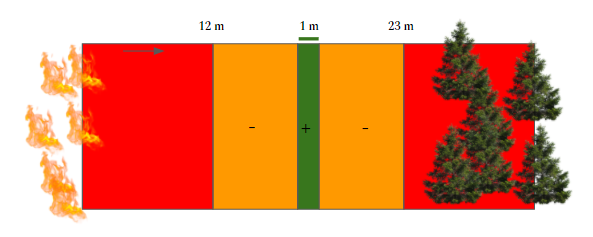
Figure 2: The variable “d” represents the distance from the fire front and “v” represents the velocity of the drone. The red regions in this diagram are where the drone receives a reward of -10 and the episode terminates. The orange region is part of the exponential decay where the drone receives a small negative reward. The 1 m across green region is also part of the exponential decay where the drone receives a small positive reward.
The images are labeled with the corresponding action the drone must take in order to continue flying parallel to the fire front. Furthermore, the data collection process was optimized to collect data across many states in order to address the distributional shift problem experienced by a behavioral cloning agent. Distributional shift is when the distribution of states observed by the agent operating in the environment deviates from the distribution of states present in the training data. Five different cases for the location of the drone were considered when collecting data in the environment. In each of the five cases, the drone was equipped with three cameras: forward-facing camera, left-facing camera and right-facing camera. Images from each camera are labelled based on the drone’s distance from the fire front. Figure 3 shows the labels assigned to the images from each in camera in all the cases.
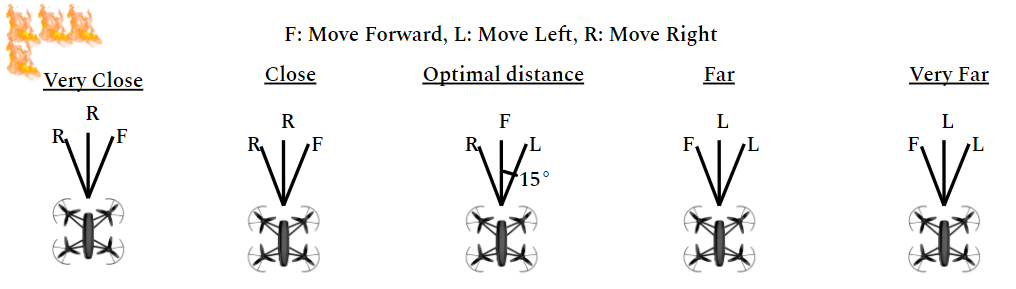
Figure 3: This diagram demonstrates how the images are labelled from the three cameras in the five different cases. For example, if the drone is at the optimal distance from the fire front, images from the forward camera are labelled to go forward, images from the left camera are labelled to go right and images from the right camera are labelled to left.
from the data to map images to discrete actions allowing the drone to fly autonomously and navigate parallel to the fire front. Two different training trials were conducted. In the first training trial, 14000 images were collected from case 3 and 1500 images were collected from the remaining cases. In the second trial, 3000 images were collected from each training cases totaling 15000 images. The policy obtained from behavioral cloning is used for transfer learning i.e., the weights of the DQN are set to the weights of the behavioral cloning policy and the DQN is trained from there.
The performance of the drone is measured using the average value of the reward per episode, whether or not the drone can successfully navigate from one end to the other end of the fire front and the amount of deviation from the optimal/midpoint distance to the fire front.
Results
The addition of 700 new images increased the mean Average Precision (mAP) of YOLOv3, YOLOv3-tiny and YOLOv4 by approximately 3%.
Changing the Beta value such that the portion of the path where the drone receives positive reward is larger leads to unexpected non-optimal behaviour. The drone learns to accumulate positive reward by rotating in circles while remaining approximately in the same spot along the fire front. The drone does not fly along the fire break parallel to the fire front and does not explore/monitor new parts of the fire front other than the starting point. Figure 4 shows the graph of the reward throughout training when the positive reward section is made relatively larger.
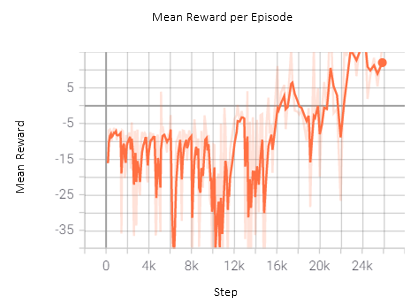
Figure 4: In the first 10k steps, the drone is just collecting data and no training is being conducted. Training starts at the 10k step and the drone quickly learns to rotate in circles to accumulate positive reward as seen by the sudden large increase in the mean reward per episode.
Another experiment was conducted where the Beta value was set to 1 so the positive reward region is only 1 meter across. Furthermore, the action space was changed so the drone moves with respect to the environment’s reference frame and the possible actions are: forward, left 90 degrees and right 90 degrees. However, in this experiment, the drone learned to repeatedly move left and right in the positive reward section while staying approximately in the same position along the fire front. Similar to the previous experiment, the drone fails to fly parallel to the fire front and does not explore/monitor new parts of the fire. Figure 5 shows the graph of the reward per episode throughout training for this experiment.
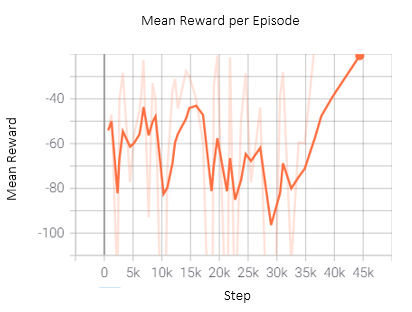
Figure 5: Similar to the previous experiment, the first 10k steps are non-training steps only for data collection. The behavior in this experiment took longer to achieve than the circular behavior. Around 30k iterations the drone learned to repeatedly move left and right to accumulate positive reward.
A subsequent experiment was conducted where the Beta value was kept at 1 but the action space was changed so the drone moves with respect to its own reference frame and the possible actions are: forward, left 15 degrees and right 15 degrees. Changing the action space by reducing the turning angle ensures the drone cannot rotate in circles without moving away from the positive reward region. This should encourage the drone to avoid rotating in circles. In this experiment, the drone was able to successfully fly along the fire front parallel to the fire break. It is able to traverse the entire fire front without crossing the threshold distances. Figure 6 shows the training graph for this experiment.
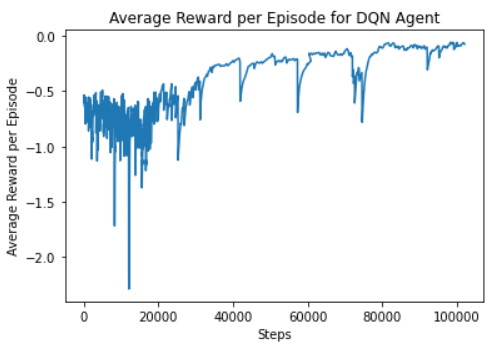
Figure 6: This graph shows the mean reward per episode averaged over the episode lengths. The agent took 100k steps to converge but the reward is still relatively volatile over different episodes. For example, there are large dips around 80k steps and smaller fluctuations from episode to episode.
a 77% validation accuracy. However, the behavioural cloning agent is not able to traverse the fire front. While the agent is able to fly parallel to the straight sections of the fire front, it is not able to adapt to curving sections. The agent fails to turn and crosses the threshold distances.
In the second training trial where the data imbalance is corrected, the behavioural cloning policy achieves a 99.63% validation accuracy. In the simulation, the behavioral cloning agent is able to successfully traverse the fire front from one end to the other end without crossing the threshold distance. The agent also is able to stay relatively close to the optimal distance. Figure 7 shows the validation loss and accuracy during training and figure 8 shows the agent evaluated in the environment.
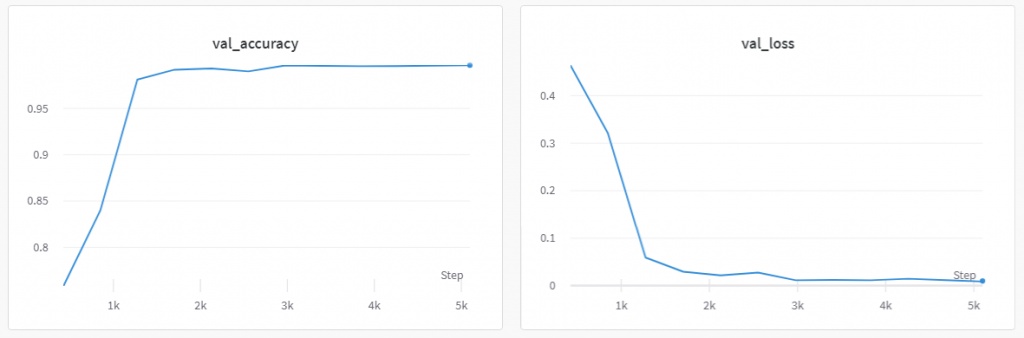
Figure 7: The validation accuracy and validation loss follow the standard learning curve for a supervised learning model. There is a large drop is validation loss (large increase in accuracy) and the loss stabilizes and converges around 5k iterations.
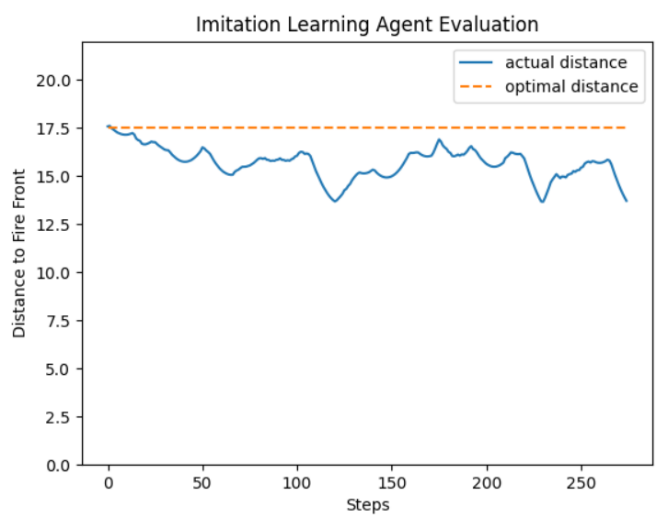
Figure 8: The imitation learning agent was able to approximately follow the fire front while staying within the threshold distances. However, it was never able to maintain a distance very close to the optimal distance and a gap of approximately 1.5 meters from the optimal distance was observed throughout the entire evaluation process.
Transfer learning was conducted to train a DQN agent by initializing the DQN with the weights of the behavioral cloning policy. This allowed the DQN to converge much faster and achieve better performance than the randomly initialized DQN agent and the behavioral cloning agent. Figure 9 shows the training graph of the mean reward per episode for the transfer learning DQN agent and figure 10 shows a graph of the agent evaluated in the environment.
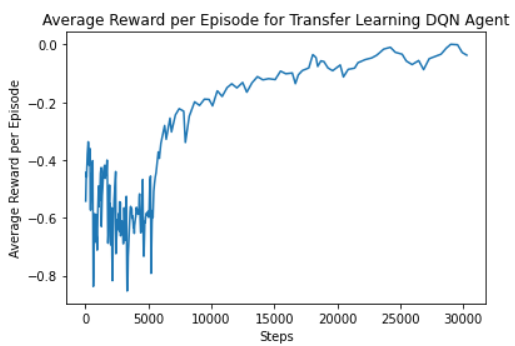
Figure 9: The mean episode reward averaged over episode lengths for the transfer learning DQN Agent converged in approximately 30k steps which is much shorter than the non-transfer learning case. Furthermore, the reward per episode is more stable and much less volatile than the non-transfer learning case.
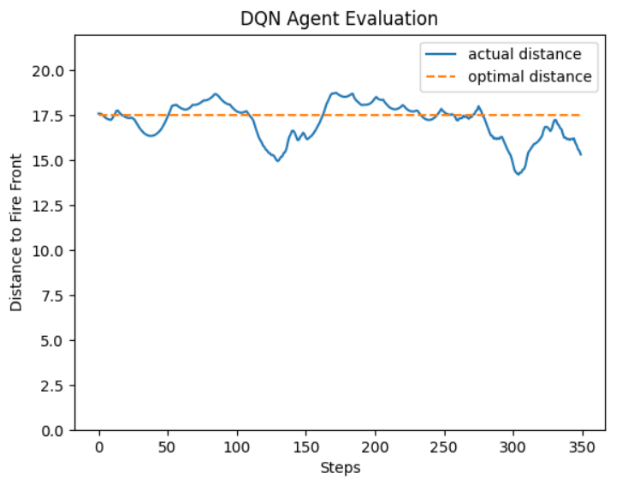
Figure 10: The transfer learning DQN agent successfully navigated from on end to the other end of the fire front without crossing the threshold distances. It was able to adapt to curving sections of the fire front and it deviated much less from the optimal distance than the transfer learning agent. The average deviation was only 0.36
Specifically, the reward for crossing the threshold distance was changed from -10 to -100. This resulted in a slight improvement to the DQN agent and allowed the DQN to converge slightly faster. Figure 11 shows the mean reward per episode for this experiment and the Figure 12 demonstrates the DQN agent obtained from this experiment evaluated in the environment.

Figure 11: The mean episode reward averaged over episode lengths is more stable and converged slightly faster in this case. However, the actual reward value is only slightly greater than the previous case.
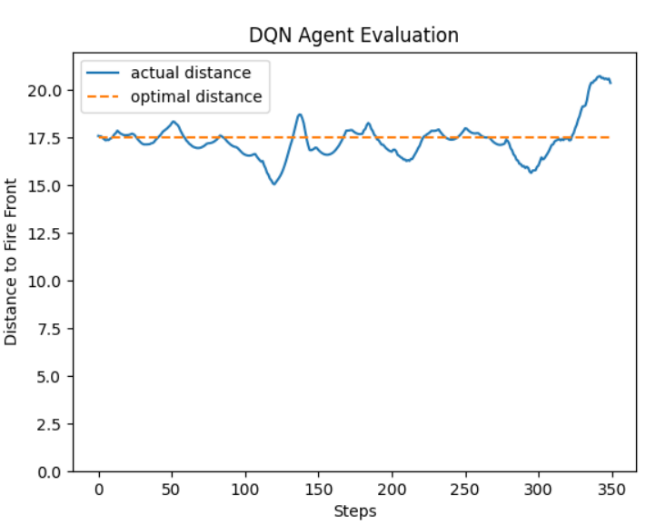
Figure 12: The DQN agent performs similarly in this case to the previous case. The graph of the actual distance shows the drone is able to stay close to the optimal distance and adapt to curving sections of the fire front.
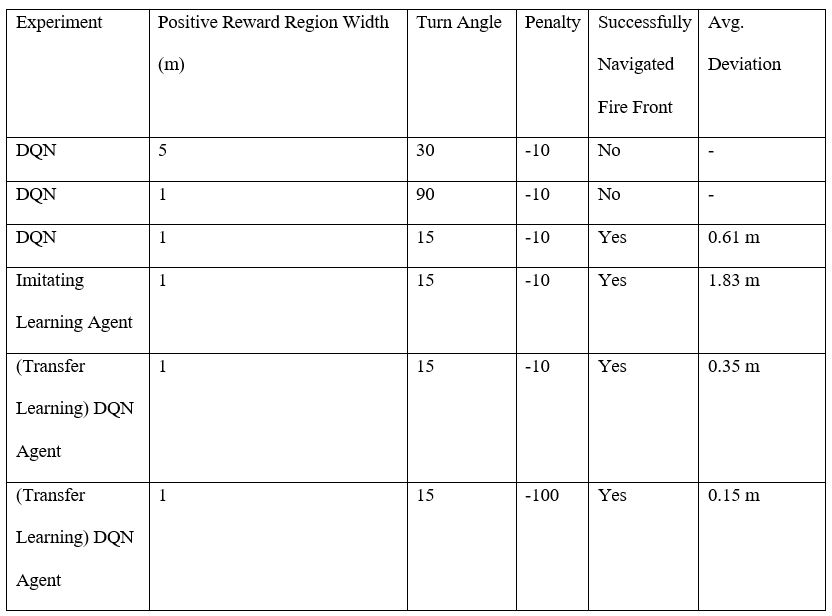
Table 1 displays a summary of the results showing the different parameters that were tuned. The average deviation from the midpoint/optimal distance was not considered if the drone could not navigate the entire front.
Table 1: In summary, the Transfer Learning DQN Agent which receives a reward of -100 for crossing the threshold distances obtains the best performance. Furthermore, the other parameters for the agent include a turning angle of 15 degrees, an average deviation of 0.36 meters and the width of the positive reward region was 1 m.
Discussion
A major portion of the project was dedicated to tuning the reward function to achieve the desired behaviour. It was determined that setting the Beta value to 1 (resulting in the positive reward region being 1 m across) causes the drone to avoid learning to take a circular path. The circular path behaviour of the drone observed when the positive reward region is larger might be a result of the complexity of the task. Following the fire break and staying parallel to the fire front (adapting to curvature etc.) is a relatively more complex task to learn that repeatedly taking the same action and going in circles. Especially during the initial stages of training, when the drone is exploring the environment, it determines that moving in circles allows for the accumulation of positive reward. Therefore, it continues to exploit this strategy and is never able to progress further and learn the optimal strategy outlined in the task. The difference in complexity is also demonstrated in the training time. The DQN agent that learned to properly complete the task and follow the fire break took 100k timesteps to converge while the DQN agent that took a circular path learned this behaviour in only 20k timesteps.
Although the experiment where the Beta value is set to 1 and the action space is changed the drone movement in the world’s reference frame did not lead to the desired behaviour, it was a baseline which provided valuable insight for further experiments. Since the drone moves based on cardinal directions, it observes very similar states when taking the same action i.e., turning west will result in the drone always facing the fire front. Due to this, flying along the fire break becomes a slightly easier task. However, since the drone could only turn in the east-west directions, it learned to go repeatedly turn east and west in the positive reward region. From this behaviour it can be determined that if the turn angle is less than 90 degrees and relatively small (i.e., a forward velocity is applied to the drone) the drone could learn to fly along the fire front. Moving based on cardinal directions may be replaced with relative movement from the drone’s own reference frame since that is more representative how drones in real life function.
A successful outcome is achieved when the Beta value is set to 1, the action space is relative to drone’s reference frame and the turning angle is 15 degrees. Having a relatively small turning angle of 15 degrees allows the drone to navigate more gentle curves of the fire front while still retaining the ability to maneuver sharper curves. Furthermore, the drone would not deviate too far from the optimal distance if it selects a wrong action. A small turning angle also allows the drone to readjust more quickly if it takes a wrong action since the state observed by taking a wrong action will only be slightly different than the previous state. All of these adjustments allow the drone to successfully navigate from one end to the other end of the fire front. Even though the drone still undergoes deviations from the optimal distance, this is not a critical issue for this task. In an outdoor setting where the drone is flying above the trees/fire/obstacles and is monitoring the fire front, small deviations do not pose a serious threat to the drone and its performance.
In the first training trial of the behavioral cloning agent, the data imbalance led to a poor validation accuracy and low performance in the environment. This may be due to the fact the model is attempting to minimize loss which is not as representative of the problem when there is an imbalanced dataset. For example, the model can learn to predict the same action(such as move forward) and it would be correct in many cases because a larger proportion of the data has the move forward label. Evaluating the behavioral cloning agent in the environment further supports this reasoning. The agent takes the same action (move forward) in most cases. This works well when the fire front is straight but when the fire front is curving, moving forward causes the drone to cross the threshold distances.
Correcting the data imbalance results in much better performance since the model learned to predict various actions for the cases present in the training data. Although the behavioral cloning agent in training trial 2 is able to traverse the fire front, there is often a relatively large gap between the optimal distance and the actual distance. This is possibly caused by the limited number of cases used to collect training data. Only 5 different distances are considered so the drone has difficulty determining what action to take in between those distances. Collecting data from more distances may mitigate this problem.
Transfer learning using a pretrained behavioral cloning policy is very useful as the DQN does not have to learn from scratch to recognize patterns or features in the images. Furthermore, since the pretrained agent has already been trained to extract features from images to take actions, the DQN agent will take fewer random actions. Starting from more expected behaviour allows the agent to converge faster and optimize towards a better performance.
Simulated testing of autonomous wildfire drones using imitation learning, reinforcement learning and traditional automation methods such as GPS navigation produces promising results. Using these techniques, the drone learned to navigate the entirety of the fire front while maintaining a consistent distance from the fire front with very little deviations. This demonstrates potential for practical application of autonomous wildfire drones to monitor and survey stabilized fire fronts along a fire break.
It’s important to consider that the simulation lacks details that are present in reality and is limited by the physics engine of the platform. Certain parameters such as the speed and height of the drone are kept constant and ideal weather conditions and with no wind were assumed which is not necessarily consistent with real life. Furthermore, the results for autonomous drones are restricted to a stabilized fire front where the wildfire is mostly under control rather than a highly active wildfire. Real life testing of the drone with controlled fires also needs to done to validate the results of this project.
Future work can implement a more complex simulation environment to include factors such as wind and different weather and lighting conditions. In addition to a more complex simulation environment, real life flight data and near infrared (NIR) images can be obtained from human operated drones in the field. Near infrared provides increased visibility of the fire by removing smoke in the captured images. The flight data combined with NIR images can be used to train a behavioral cloning policy. This policy can be used to conduct transfer learning to train a reinforcement learning policy in the more complex environment. Additional reinforcement learning algorithms such as actor-critic and policy gradients can be tested. Furthermore, the policy can be improved by providing more information and context about the environment. For example, frame stacking (inputting images from previous states) and multiple cameras can be used. Data from wind sensors, accelerometer and gyroscope on the drone can be inputted into the policy. Fire detections made by the object detection models can also serve as inputs to the policy network to enhance the feature extraction capability of the network.
In this paper, I have presented a lightweight video-based fire detection system by leveraging the advantages of deep learning. Several different experiments were conducted with imitation learning and deep reinforcement learning agents to automate wildfire drones in a simulated environment. By tuning the reward function, optimizing data collection and implementing transfer learning the drone is successfully trained using deep reinforcement learning to navigate the entire fire front and monitor the wildfire.
References
Afghah, F., Razi, A., Chakareski, J., & Ashdown, J. (2019). “Wildfire Monitoring in Remote Areas using Autonomous Unmanned Aerial Vehicles.” IEEE INFOCOM 2019 – IEEE Conference on Computer Communications Workshops (INFOCOM WKSHPS).
Apvrille, L., Tanzi, T., Dugelay, J.C. (2014). “Autonomous Drones for Assisting Rescue Services within the Context of Natural Disasters.” 2014 XXXIth URSI General Assembly and Scientific Symposium (URSI GASS).
BC Wildfire Service. (2020, Mar. 31) “Wildfire Averages.” Statistics and Geospatial Data.
Muhammad K., Ahmad, J., Mehmood I., Rho S., and Baik S. W. (2018, March 6). “Convolutional Neural Networks Based Fire Detection in Surveillance Videos.” IEEE Access, 6, 18174–18183.
Phillips, W., Shah, M., and Lobo, N.V. (2002). “Flame Recognition in Video.” Pattern Recognition Letters, 23(3), 319–327.
Redmon, J., and Farhadi, A. (2017, Dec. 6). “YOLO9000: Better, Faster, Stronger.” 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR).
Savvides, L. “Fighting Fire with Fliers: How Drones Are Combating California’s Record Wildfires.” CNET, CNET, 27 Aug. 2018, www.cnet.com/news/californias-fires-face-anew-high-tech-foe-drones.
Shah, S., Dey, D., Lovett, C., & Kapoor, A. (2017). AirSim: High-Fidelity Visual and Physical Simulation for Autonomous Vehicles. Field and Service Robotics Springer Proceedings in Advanced Robotics, 621-635.
Shen, L. (2018, Nov. 30) “Here’s How Drones Could Help With California’s Wildfire Problems.” Fortune. fortune.com/2018/11/29/drones-wildfires-california-drones/.
Statistics Canada. (2019, Oct. 30) “Wildfires.” Get Prepared / Préparez-Vous. www.getprepared.gc.ca/cnt/hzd/wldfrs-en.aspx.
Toulouse, T., Rossi, L., Akhloufi, M., Pieri, A., and Maldague, X. (2018). “A Multimodal 3D Framework for Fire Characteristics Estimation.” Measurement Science and Technology, 29(2).
Toulouse, T., Rossi, L., Celik, T., and Akhloufi, M. (2015). “Automatic Fire Pixel Detection Using Image Processing: a Comparative Analysis of Rule-Based and Machine LearningBased Methods.” Signal, Image and Video Processing, 10(4), 647–654.
Vidyavani , A., Dheeraj, K., Rama Mohan Reddy, M., and Naveen Kumar, KH. (2019, Oct.). “Object Detection Method Based on YOLOv3 Using Deep Learning Networks.” International Journal of Innovative Technology and Exploring Engineering Regular Issue, 9(1), 1414–1417.
Zhang, Q., Xu, J., Xu, L., and Guo, H. (2016). Deep Convolutional Neural Networks for Forest Fire Detection
Zhu, X., Liu, Z., and Yang, J. (2015). “Model of Collaborative UAV Swarm Toward Coordination and Control Mechanisms Study.” Procedia Computer Science, 51, 493–50