James Jin, Year 2 Engineering
Abstract
This project aims to provide a more flexible means of NLP mediated scientific communication. An encoder-decoder recurrent neural network is used in conjunction with attention, written in python. The project output human-readable responses specific to questions, falling within initial expectations despite necessary improvements in handling various sentence lengths. Overall, this project shows the wide range of NLP applications and is a corner stone for more advanced human-computer interaction.
Introduction
The field of artificial intelligence (AI) has one among many of its goals to mimic human speech. With the advancement in computational power and software technology, this specific subfield, known as Natural Language Processing (NLP), grew considerably over the second half of the 20th century to present day. Both the technique and sophistication of NLP improved greatly; initially, systems that both interpreted and generated (hence, Natural Language Generation, or NLG) human speech relied on rule-based programming, such as the MIT-developed ELIZA (Weizenbaum, 1966). Now, NLP algorithms consist of neural networks and utilize deep-learning techniques, creating much more flexible and humanoid behaviors. This is the approach that this project is based on.
Despite such progress, NLP is still an active field with ample ongoing research and numerous experimental projects, exploring its seemingly limitless potential. While this project doesn’t aim to develop new algorithms, it strives to apply existing NLP knowledge in new ways to address an emerging problem – scientific communication, or the lack of which. Currently, credible, unprejudiced scientific information usually appear in abstruse and undigestible formats, such as scholarly journals and encyclopaedia. For people uninvolved in science, access to contemporary scientific knowledge is often challenging. This project explores the possibility of conveying scientific information through a conversation, which could retain both ease of understanding and accuracy of knowledge.
In order to fulfill this aim, the project employs prevalent NLP and general machine learning algorithms and adapt them to allow the “intelligent” generation of speech (i.e., without relying on pre-programmed templates or rules). This characteristic does, however, require extensive input of established data (a.k.a training) regarding conversations of scientific topics, and the algorithm itself isn’t omniscient. Upon completion, the project should provide a spontaneous answer to every question asked. Currently, there are many other examples of applying NLP to address a real-world need. Aside from eminent products such as Google Assistant or Siri, other non-commercial, research-intended projects include Carnegie Mellon University’s Read-The-Web (Mitchell et. al, 2015). These adaptations of existing technology to new purposes certainly have feasibility yet significance. Inspired by existing achievements, this project aims to open a new path towards scientific communication.
Materials and Methods
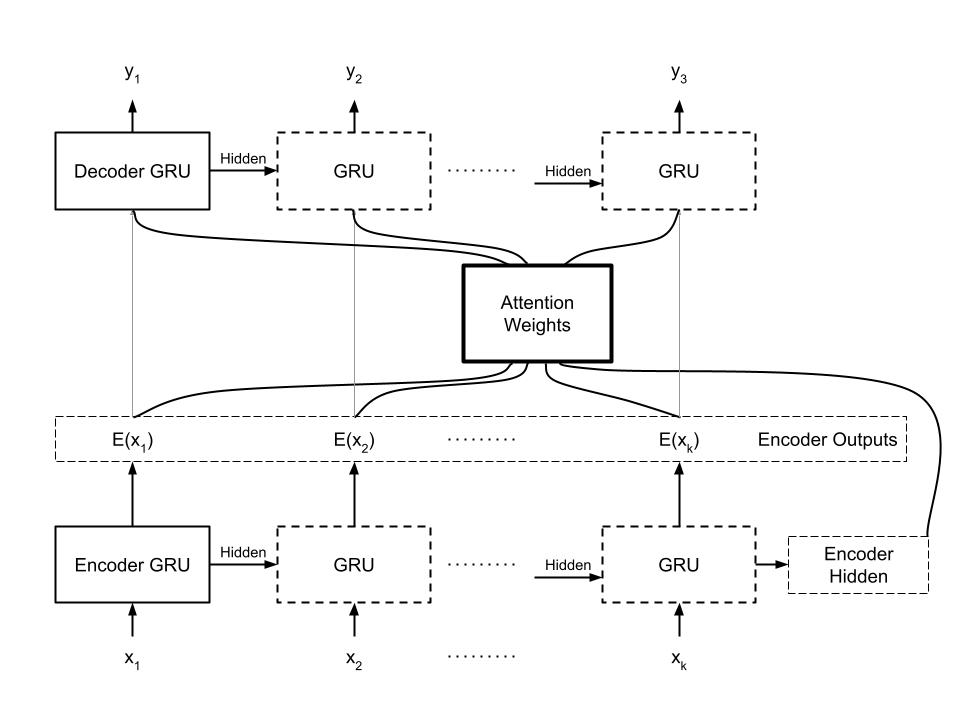
Figure 1: The structure of the final algorithm
Due to the fact that this project is a software, it doesn’t have any specific hardware requirements, and almost all of the complexity arises from the construction of the software itself. As background information, this specific instance of the project was carried out on a HP-Pavillion 22-a109 with an Intel(R) Pentium (R) CPU G3260T @ 2.90GHz and 8.00 GB of RAM.
In terms of software, the program was written in Python in the integrated development environment known as Spyder. To enable the usage of neural networks, development includes the open-source library of Pytorch. Due to the nature of using neural networks and machine learning, the program has two distinct parts. The first of which is the architecture of the neural network itself. As stated in the introduction, this project aims to creatively apply existing NLP techniques. The network’s architecture classifies under that of an encoder-decoder (Cho et. al. 2014) recurrent neural network with an added attention mechanism (Zhang et. al. 2017) in the decoder portion. The principle of this network is reducing (encode) the input to an abstract synopsis (known as the “latent” vector) and then expanding (decode) the vector to an understandable output; the attention mechanism enables the decoder to focus on certain parts of the input sequence, which ease the decoding process. Within from the encoder-decoder framework, the recurrent neural network itself is also a special Gated Recurrent Unit (GRU), which has three sets of weights rather than the traditional one with better memory of previously processed data.
To suit the needs of this project, the encoder must read input sentences as a list of numbers (a “tensor”) with dimensions of n x 1 (n is the sentence length); each number corresponds to a unique word in the English language. Then, embedding (analogous to a look-up table) transforms the input tensor to a fixed dimension of 1 x 1 x k, where hyperparameter k is the length of the recurrent neural network’s hidden layer. Subsequently, the embedded input and hidden layer enters the GRU, producing an output, which a tensor records, and updating the hidden layer. After the encoder processes every word of the input sentence, both the hidden layer and the tensor of encoder outputs transfer to the decoder. Due to the implementation of the attention mechanism, the decoder input and preserved encoder hidden layer derives an additional set of attention weights to be applied to decoder inputs. This process concatenates the hidden layer to the embedded input tensor and linearly transforms the result to a dimension of 1 x m, where hyperparameter m denotes the maximum length of the input. Afterwards, this tensor of attention weights is applied to the encoder outputs through binary matrix multiplication, and this applied attention is concatenated to the embedded decoder input and linearly transformed to 1 x 1 x k. After the attention mechanism, the post-attention decoder input undergoes the Rectified Linear Unit (ReLU), and both the input and hidden layer enters the GRU, producing an output and an updated hidden layer. Then, the output is linearly transformed to a dimension of 1 x c, where c is the total number of words registered by the algorithm and the size of the output. Finally, the output undergoes the log softmax function.
The second part of the software is the training of the aforementioned neural network, allowing it to learn speech and scientific knowledge. This is accomplished by using training data composed of questions and their respective answers, giving the network a goal to evaluate its performance. The distance between current performance and the goal is kept track of by a loss function. For this project, since the decoder has a log softmax as its final layer, the loss function is the negative likelihood loss (NLLLoss) (Durán Tovar 2019). In each training cycle, the network receives an input question; then, the encoder processes the input to produce a latent vector as described in the previous paragraph, which is passed on to the decoder; subsequently, the output from the decoder is judged against the target output by the loss function. After the loss’s calculation, the weights of the neural network are automatically updated via the Adam optimizer (Brownlee, 2017) built into the Pytorch library. Over a large number (ex. 10000) of training cycles, the network can produce meaningful outputs.
Results
To evaluate the performance of the algorithm, the loss function is used to determine the proximity of the program’s output to the target output (the answer provided by a human). Since loss functions can only compare numeric data, the target output is converted into its numeric representation in the same manner as the input’s conversion before encoding. The project is performing well when the loss approaches zero. During testing, 100 inputs that the algorithm hasn’t encountered during training were given, and the loss for each output was calculated. The input sentences gradually lengthen.
Table 1: The Average Loss of Every 10 Trials
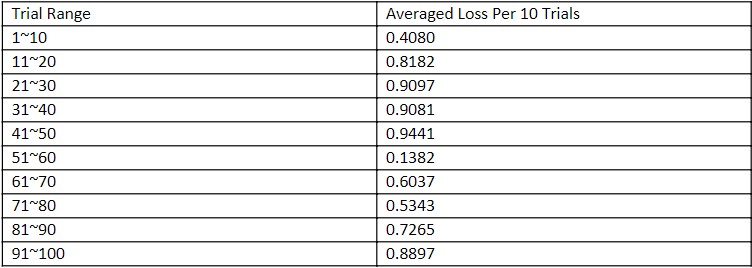
The overall average of the loss is 0.6881. The individual averages are highest in trial range 31~40 and lowest in trial range 51~60. The overall trend increases across trials and thus input length, except for a drastic drop between input 41~50 and 51~60.
The project is also tested by the grammatical correctness of its outputs. Output sentences were placed into a document in Microsoft Word, which automatically checks for grammar errors. The same outputs previously tested for their loss are used. The ratio between number of mistakes and sentences is calculated, with a lower number being better.
Table 2: Grammar Correctness Score of Every 10 Inputs
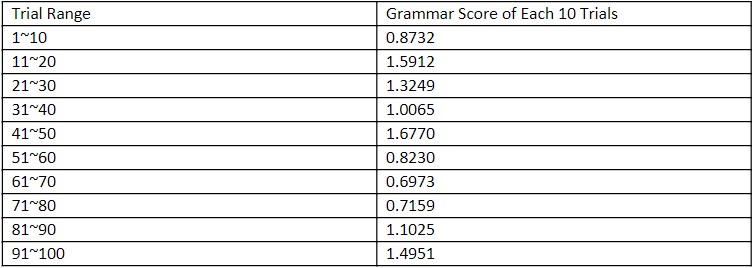
The score is the lowest (ie. best) at 51~60 to 71~80 and 1~10. There is a steady increasing (worsening) trend from 1 to 50. The score then improves at 51 and again increases towards 100.
Discussion
In general, the project performed towards its intentions. The end result was able to respond to unfamiliar questions with adequate coherence. This is an important distinction from directly storing data in a database that the program accesses under specific, rigid circumstances. The project successfully allowed the algorithm to store knowledge through the learning of its various weights, allowing for much more flexible and nuanced response than simply giving the program predetermined criteria to respond in fixed ways. The merit of this approach is also its flaw, since the program can only store knowledge through the adjustment of its limited number of weights. Without the ability to self-expand its architecture, the algorithm can only learn a finite amount of information.
This characteristic of using limited knowledge creatively is revealed through the results. While the program responds to medium length sentences with variety, it struggles to respond to longer sentences with more clauses. This phenomenon can be explained as the program simply doesn’t have the knowledge to answer more challenging questions. Thus, just like a human being, the program can creatively meet demands within its capabilities but cannot immediately satisfy more stringent demands outside of what it has experienced in the past. Nevertheless, the program does have many possibilities of improvement, and if this project is to be done again, a paramount addition to the current algorithm is learning autonomously without the operator designating the data source to learn from.
Falling under the overall goal of a strong AI, this project proves the possibility of understanding and generating human speech. To further advance towards this goal, any human-computer interaction software needs to formulate its own conclusions or even opinions. This project hasn’t reached this level of sentience yet, since the decoded output is only based on the encoded information from the input alone, without other sources of existing data. In other words, the program can only react to human input and cannot proactively initiate dialogue. Nevertheless, this and other similar projects can serve as future components of a much more extensive software that allows computer to have independent thought.
Finally, this project does show that it’s possible for software to retain and convey, if not produce, knowledge while learning through exposure to information. This property holds true even under various kinds of knowledge to be learned, as this project’s scientific communication purpose adds another possibility to the wide range of existing applications of NLP.
References
Brownlee, Jason. “Gentle Introduction to the Adam Optimization Algorithm for Deep Learning”. Machine Learning Mastery, July 3, 2017. April, 2021.
K. Cho et. al. “On the Properties of Neural Machine Translation: Encoder-Decoder Approaches”, Proceedings of SSST-8, Eighth Workshop on Syntax, Semantics and Structure in Statistical Translation. September, 2014. Pp. 103-111. doi: 10.3115/v1/W14-4012
Durán Tovar, Alvaro. “Negative log likelihood explained”. Deep Learning Made Easy, August 13, 2019. Medium. April, 2021.
T. Mitchell et. al. “Never-Ending Learning”, In Proceedings of the Conference on Artificial Intelligence (AAAI), 2015. doi: 10.1145/3191513
Weizenbaum, Joseph. “ELIZA–A Computer Program For the Study of Natural Language Communication Between Man and Machine”, Communications of the ACM. Janurary, 1966. doi: 10.1145/365153.365168
J. Zhang, J. Du and L. Dai, “A GRU-Based Encoder-Decoder Approach with Attention for Online Handwritten Mathematical Expression Recognition,” 2017 14th IAPR International Conference on Document Analysis and Recognition (ICDAR), 2017, pp. 902-907, doi: 10.1109/ICDAR.2017.152.